原文:Zoe,Puzzle Ventures
从众多公链展开竞争以来,到以太坊路线图中的 Danksharding,再到 op/zk 等二层解决方案,我们一直不间断在讨论区块链的扩展性——大量用户和资金进来了怎么办?通过接下来一系列的文章,我想向大家展示一个未来的图景,该图景由数据的获取、链下计算、链上验证三部分构成。
Trustless Data Access Off-chain Computation On-chain Verification
「证明共识」是这个蓝图中重要的一部分。本文探讨了在以太坊 PoS 的基础上,用零知识证明共识的意义,包括:
1. 对于 EVM 去中心化的重要性。
2. 去中心化数据访问对于 web3 扩容的重要性。
证明以太坊主网的全共识是一项复杂的任务,但是如果我们能够实现共识层的 zk 化,将会在确保安全信任的基础上助力以太坊的扩容,同时增强整个以太坊生态的稳健性,降低参与成本,让更多人融入其中。
利用 zk 来验证以太坊 L1 的共识层在两个大方向上有意义。首先,它可以弥补当前节点多样性的缺陷,增强以太坊本身的去中心化和安全性。其次,它为以太坊生态各层协议面对更多用户提供了可用性和安全性的基础,包括跨链安全、无需信任的数据访问、去中心化预言机、和扩容等方面。
对于以太坊来说,要实现其去中心化和稳健性 (robustness),它需要一个客户端多样性的环境。意味着更多的人参与其中,尤其是普通用户,运行基于不同代码环境的客户端。然而,要求每个用户都运行全节点是不现实的,因为这需要大量的资源,没有几个人能够承担至少 16 GB RAM 和 Fast SSD with 2 TB,而这些要求还在不断增长。
目前的目标是实现轻节点 (light node),既能提供与全节点相同的信任度(信任最小化),又能在内存、存储和带宽要求上具有更低的成本。然而,目前轻节点并不参与共识过程,或者说只受到部分的共识机制保护 (Sync Committee)。
这一目标在以太坊的路线图中被称为「The Verge」。
Goal: verifying blocks should be super easy - download N bytes of data, perform a few basic computations, verify a SNARK and you’re done— The Verge on Ethereum’s Roadmap
「The Verge」旨在弥合客户端差距,关键步骤是如何实现去信任的轻节点,安全程度应等同于今天的全节点,填补「the client gap」,从而让更多人积极参与网络的去中心化和稳健性。
Stacks on Ethereum
从第一性原理出发,我们需要解决链上数据访问与链下计算验证的结合问题。
目前链上数据的使用相对初级,不够充分。在很多情况下,协议调整所需的数据过于复杂,无法进行链上计算,而以去信任方式获取数据的成本又过高,需要大量历史数据访问和频繁的数字计算等。
对于个人用户和项目来说,我们的理想情况是实现去中心化的、端到端的无需信任假设数据传递和读写,以此为基础,面向未来更多的用户,应实现尽量低的计算成本,兼顾安全性、可用性和经济性。
具体包括以下几个方面:
1. 去中心化和无需信任的预言机 (Oracle):目前的协议使用中心化预言机来避免直接在链上对大量历史数据的访问,增加了不必要的信任成本,并降低了可组合性。
2. 数据和资产敏感相关协议的数据读写:例如,DeFi 协议在运行过程中需要进行一些参数动态调整,但是否能够无需信任地访问历史数据并进行更复杂的计算,如基于最近的市场波动调整 AMM 费用,设计链上衍生品交易价格模型和动态波动,引入机器学习方法进行资产管理,根据市场情况调整借贷利息等。
3. 跨链安全:目前基于 zk 技术的轻节点方案在安全性 (security)、资金效率 (capital efficiency)、状态保留程度 (statefulness) 和传递信息多样性方面都更优秀。当前 Succinct 的 Telepathy 跨链方案和 Polehedra 在 LayerZero 上面做的跨链方案,都是基于 Sync Committee 做的轻节点区块头 zk 验证。然而,Sync Committee 并非以太坊 PoS 共识层本身,存在一定的信任假设,未来还有余地可以做的更加完备。
目前,由于经济成本、技术限制和用户体验等方面的考虑,开发者在利用链上数据时通常依赖于中心化的 RPC 服务器,例如 Alchemy、Infura 和 Ankr 等。
区块链中的计算数据有两种来源:链上数据 (on-chain data) 和链下数据 (off-chain data)。对应链上和链下两种去向,进行计算。比如前文提到的调整 DeFi 协议参数的需求。
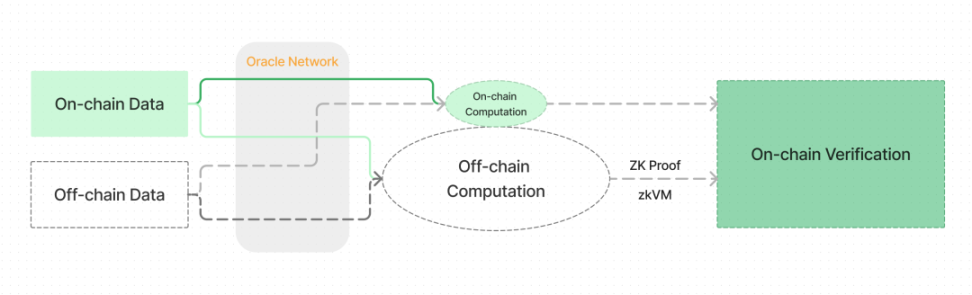
Verify)」。
2. 往往涉及许多复杂和昂贵的计算过程。
如果没有找到合适的技术解决方案,以上两点便会影响区块链的可用性。
我们可以通过一个简单的例子来说明不同数据获取方式。假设你想查看自己的账户余额,你会怎么做?
一种最安全的方式是自己运行一个全节点,检查本地存储的以太坊状态,并从中获取账户余额。
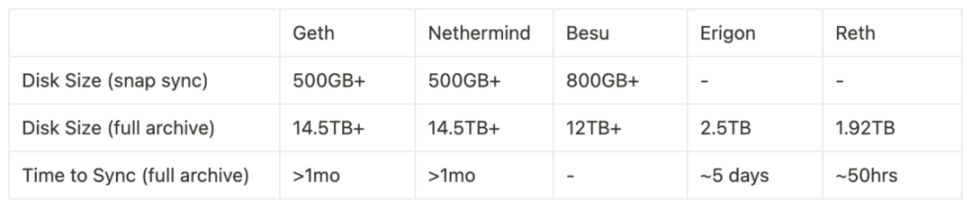
全节点 Benchmark。同步模式 (sync mode) 和客户端选择会影响所需的空间要求。参考: https://ethereum.org/en/developers/docs/nodes-and-clients/run-a-node/; https://docs.google.com/presentation/d/ 1 ZxEp 6 Go 5 XqTZxQFYTYYnzyd 97 JKbcXlA 6 O 2 s 4 RI 9 jr 4 /mobilepresent?pli=1&slide=id.g252b bdac 496 _ 0 _ 109)
然而,自己运行全节点的成本很高,还需要自己维护。为了省事,很多人可能会直接向中心化的节点运营商请求数据。虽然这样做没有什么问题,类似于 Web2 中的操作,而且我们也从未见过这些供应商有过任何恶意行为,但是这也意味着我们必须相信一个中心化的服务商,这增加了整体的安全假设。
为了解决这个问题,我们可以考虑两个解决方案:一是降低运行节点的成本,二是寻找一种验证第三方数据可信度的方法。
那不如就只存储必要的数据。为了更高效地访问数据,降低信任成本,并独立验证数据,一些机构开发了轻客户端 (light clients),如 Rust-based Helio(由 a16z 开发)、Lodestar、Nimbus 和基于 JavaScript 的 Kevlar 等。轻客户端不存储所有的区块数据,而只下载和存储区块头——一个区块全部信息的「总结」。轻客户端能够独立验证接收到的数据信息,因此当从第三方数据提供商获取数据后,你不再需要完全信任该提供商的数据。
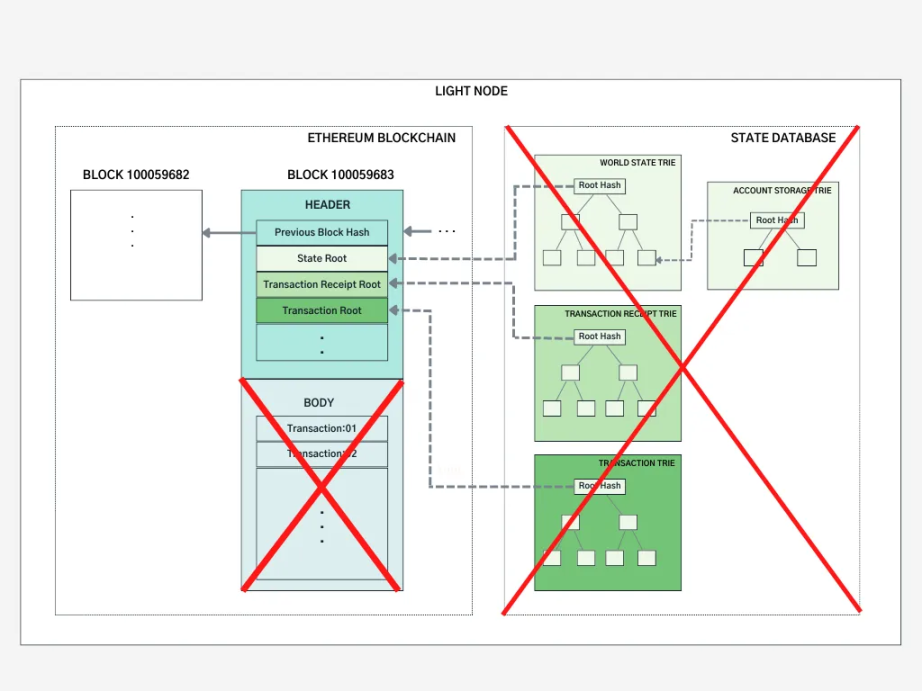
理想情况下,轻节点可以在手机或嵌入式设备上运行。
理想情况下,它们可以与全节点具有相同的功能和安全保障。
但是轻节点不参与共识过程,或者说只受到部分的共识机制保护,即同步委员会 (Sync Committee)。
Sync Committee 是轻节点的信任假设。
在 The Merge 之前,从 2020 年 12 月开始,Beacon Chain 进行了一个名为 Altair 的硬分叉,其核心目的是为轻节点提供共识支持。和 PoS 全共识不同,组成这一组验证者 ( 512 个 ) 的是一个较小的数据集,相隔更长的时间段 ( 256 个 epoch,约 27 小时 ) 进行随机抽取。
Light clients such as Helios and Succinct are taking steps toward solving the problem, but a light client is far from a fully verifying node: a light client merely verifies the signatures of a random subset of validators called the sync committee, and does not verify that the chain actually follows the protocol rules. To bring us to a world where users can actually verify that the chain follows the rules, we would have to do something different.How will Ethereum's multi-client philosophy interact with ZK-EVMs?, by Vitalik Buterin*
这就是为什么我们要验证以太坊的全部共识层,以期迎来一个更加安全、可用性更强、拥有更多样化协议、以及大规模采用的未来,目前来看最好的解决方案零知识 (zero-knowledge) 技术。
要构建一个无需信任假设的环境,必须解决轻节点可信度、去中心化数据访问、和链下计算验证这些问题,在这些方面零知识证明是目前最被认可的核心技术,其中涉及到但不限于 zkEVM、zkWASM、其他 zkVM、zk Co-processor 等底层解决方案。
证明共识层是其中重要一环。
PoS 算法非常复杂,以 ZK 方式实现它们需要大量的工程工作和架构考虑,我们先将其组件进行拆分。
(1)验证者 (validator) 相关算法
其中包括以下步骤
成为验证者:验证者候选人需向存款合约发送 32 ETH,并等待至少 16 小时至几天或几周的时间,以使信标链(Beacon Chain)处理并激活成为正式验证者。( 可参考 FAQ - Why does it take so long for a validator to be activated)
行使验证职责:涉及随机数和区块证明算法。
退出验证者角色:退出验证者的方式可以是自愿退出或者因违规而被处罚 (slashed)。验证者可以随时主动发起「退出」,每个 epoch 对于退出的验证者数量有限制。如果有过多的验证者同时尝试退出,他们将被放入一个队列中,在排到之前,他们仍然需要履行验证职责。成功退出后,经过 1/8 个 eek,验证者将能够提取质押资金。
(2)随机数相关算法
每个 epoch 包含 32 个区块 (slot),提前 2 个 Epoch 进行随机分组,将所有验证者分成 32 个委员会 (committee),在当前 epoch 行使职责,分别对每个区块的共识负责。
每个委员会中有两种角色,一个提议者 (Proposer),其余为区块构建者 (Builders),也被随机选出。这样将交易排序和区块构建两个过程分离开来 ( 详见 proposer/builder separation - PBS)。
(3)区块证明 (Block Attestation) 和 BLS 签名相关算法
签名部分是共识层最核心的部分。
每个 slot 的验证委员会给投票 ( 使用 BLS 签名 ),需要获得 2/3 的通过率才能构建区块。
在以太坊 PoS 共识层中,BLS 签名使用 BLS 12 – 381 椭圆曲线,pairing-friendly, 适合聚合所有签名,减少证明时间和大小。
在工作量证明中,区块可能会发生重组 (re-org)。在合并之后,引入了执行层上的「最终化 (finalized) 区块和安全头 (safe head)」的概念。要创建一个冲突的区块 (conflicting block);攻击者需要销毁至少总质押以太币的 1/3 ;很大程度上,PoS 比 PoW 更可靠。

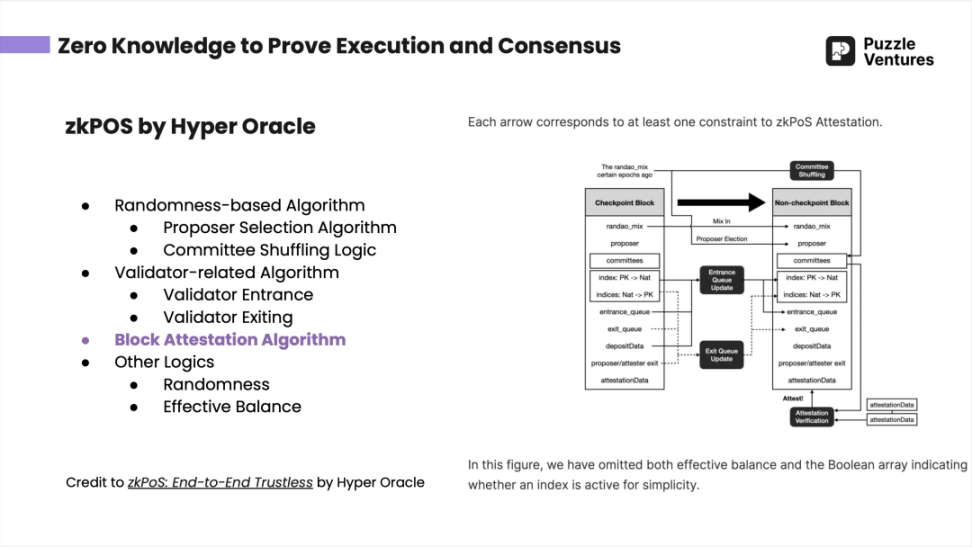
2023 年 6 月底,《Puzzle Ventures 晚自习》中间介绍到了 Hyper Oracle 的 zkPoS ( 用 zk 的方法去验证以太坊全共识层 )。详情请见 zkPoS: End-to-End Trustless
(4)其他:如弱主观性检查点 (weak subjectivity checkpoints)
无需信任的 PoS 共识证明面临的其中一个挑战是若主观性 checkpoint 的选择,涉及到社会层面的共识 (social consensus based on social information)。这些检查点是回退限制 (revert limits),因为位于弱主观性检查点之前的区块无法更改。详见:https://ethereum.org/en/developers/docs/consensus-mechanisms/pos/weak-subjectivity/
检查点 (checkpoints) 也是共识层 zk 化当中一个需要考虑的点。
在证明共识层中,证明签名或其他计算本身是非常昂贵的,但相较之下验证零知识证明却十分便宜。
在选择使用零知识证明共识层的方法时,协议需要考虑以下因素:
你要证明什么?
证明之后的应用场景是什么?
如何提高证明的效率?
以 Hyper Oracle 为例,对于证明 BLS 签名,选择了 Halo 2 ,他们选择了 Halo 2 而不是 Succinct Labs 使用的 Circom,出于以下几个原因:
Circom 和 Halo 2 都可以生成 BLS 签名(BLS 12 – 381 椭圆曲线)的零知识证明。
Hyper Oracle 并不只是干 zkPoS 这一件事,其核心产品是可编程的链上零知识预言机 (Programmable Onchain zkOracle)。其中直接面向用户的有 zkGraph、zkIndexing 和 zkAutomation,并且还利用 zkWASM 虚拟机去验证链下计算。尽管 Circom 对于工程师来说更易上手,但兼容性较差,无法确保所有功能的逻辑都能使用
Circom-pairing 会被编译成为 R 1 CS, 与 zkWASM 和其他电路的 Plonkish 约束系统不兼容,而 Halo 2 Pairing 电路能够非常容易地整合进 zkWASM 电路;相比之下,R 1 CS 对于批处理证明 (Proof Batching) 也并不理想。
从效率的角度,Halo 2-pairing 生成的 BLS 电路更小,证明时长更短,对硬件要求更低,gas fee 也更低。

https://mirror.xyz/hyperoracleblog.eth/lAE9erAz5eIlQZ346PG 6 tfh 7 Q 6 xy 59 bmA_kFNr -l 6 dE
用零知识来证明共识层的另一个关键点在于递归证明 (recursive proof) —— 即证明之证明 (proofs of proofs),把之前发生的事情打包成一个证明。
如果没有递归证明,最终会输出 O(block height) 大小的证明,即每个区块证明 (block attestation) 和相对应的 zkp 。通过递归证明,除了初始状态和最终状态外,对于任意数量的区块,我们只需要 O( 1) 大小的证明。
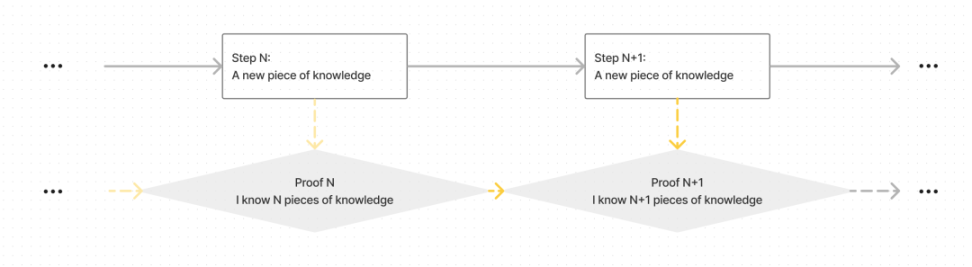
Verify Proof N and Step N 1 to get Proof N 1, i.e. you know N 1 pieces of knowledge, instead of verify all N Steps separately.
回到最初的目标,我们的解决方案应该针对有计算和内存限制的「轻客户端」。即使每个证明可以在固定的时间内进行验证,如果区块和证明的数量累加,验证时间将变得非常长。
以太坊的目标不仅仅是证明共识层,还希望通过 zkEVM 实现整个 Layer 1 虚拟机的零知识化,并最终实现多样化的 zkEVM,以增强以太坊的去中心化和鲁棒性 (robustness)。
针对这些问题,以太坊当前的解决方案和路线图如下:
「轻量化 light」—— 更小的内存、存储和带宽要求
目前通过轻节点 (light node) 实现仅存储和验证区块头 (block header) 的方式。
未来的发展还需要在 verkle tree 和 stateless clients 方面做进一步的努力,涉及改进主网数据结构。
「安全去信任 trustless」—— 实现与全节点相同的最小信任 (trust-minimization)
目前已经实现基础的轻节点共识层,即同步委员会 (Sync Committees),但这只是一个过渡方案。
使用 SNARK 来验证以太坊 Layer 1 ,包括验证执行层的 Verkle Proof、验证共识层、以及将整个虚拟机进行 SNARK 化。
Level 1 zkEVM 用于实现整个以太坊 Layer 1 虚拟机的零知识化,且实现 zkEVM 的多样化。
可能的风险
在理想情况下,当进入 zk 时代时,我们需要多种开源的 zkEVM —— 不同的客户端具有不同的 zkEVM 实现,每个客户端在接受一个区块之前会等待与其自身实现兼容的证明。
然而,多种证明系统可能会面临一些问题,因为每种证明系统都需要一个点对点网络,一个只支持某一种证明系统的客户端只能等待相应类型的证明,才能被其验证器 (verifier) 所识别。其中可能出现的两个主要挑战包括「延迟挑战 (latency challenge)」和「数据低效 (data inefficiency)」,前者主要源于生成证明很慢,在生成针对不同证明系统的证明时,有一段时间差留给作恶者创建临时分叉;后者因为你要生成多种类型的 zk 证明,就得保存原始签名,虽然理论上 zkSNARK 本身的优势是可以删除原始签名等数据,这里就出现了一些矛盾需要优化和解决。
要让 web3 迎来更多用户、提供更流畅的体验、创造更高的可用性和保障应用的安全性,我们必须为去中心化数据访问、链下计算、链上验证做好基础设施建设。
证明共识层是其中一个重要组成部分,除了以太坊 PSE 和前面提到的 zkEVM layer 2 之外,还有一些协议正在通过零知识证明共识来实现自己的应用端目标,包括 Hyper Oracle (Programmable zkOracle Network) 计划使用零知识证明以太坊 PoS 的全部共识层来获取数据;Succinct Labs 的 Telepathy 是一个轻节点桥 (Light Node Bridge) ,通过验证 Sync Committee 共识,提交 state validity proof 来达到跨链通讯的比目的;Polyhedra 原本也是轻节点桥,但现在也声明利用 devirgo 实现了全节点全共识的 zk 证明。
除了跨链安全、去中心化预言机之外,这种链下计算 链上验证的方式,也可能参与到乐观 rollup 中 fraud proof 当中,与 OP L2 相互融合;或在 基于意图的架构 (intent-based architecture) 中,针对更复杂的意图结构提供链上证明等等。
这里我们谈论的是不仅限于以太坊的链下生态系统 (off-chain ecosystem surrounding Ethereum),还涉及到以太坊以外的更广阔市场。
这个话题仍然有很多值得深入研究的部分,比方说上周 8 月 24 日 a16z 才发表了一篇认为「无状态区块链 (stateless blockchain) 无法到达」的文章,再比如说弱主观性检查点 (weak subjectivity checkpoints)、Sync Committee 安全性在数学上到底如何是否够用等问题。
再次感谢各位同僚的指教和反馈,Alex @ IOBC (@looksrare_eth), Fan Zhang @ Yale University (@0x FanZhang), Roy @ Aki Protocol (@aki_protocol), Zhixiong Pan @ ChainFeeds (@nake 13), Suning Yao @ Hyper Oracle (@msfew_eth), Qi Zhou @ EthStorage (@qc_qizhou), Sinka @ Delphinus (@DelphinusLab), Shumo @ Manta (@shumochu)
、









