作者:Steven Wang
Deep neural networks are completely flexible by design, and there really are no fixed rules when it comes to model architecture.
-- David Foster
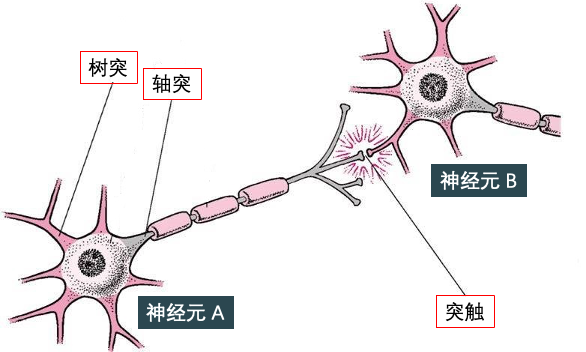
神经网络 (neural network) 受到人脑的启发,可模仿生物神经元相互传递信号。神经网络就是由神经元组成的系统。如下图所示,神经元有许多树突 (dendrite) 用来输入,有一个轴突 (axon) 用来输出。它具有两个最主要的特性:兴奋性和传导性:
兴奋性是指当刺激强度未达到某一阈限值时,神经冲动不会发生;而当刺激强度达到该值时,神经冲动发生并能瞬时达到最大强度。
传导性是指相邻神经元靠其间一小空隙进行传导。这一小空隙,叫做突触 (synapse),其作用在于传递不同神经元之间的神经冲动,下图突触将神经元 A 和 B 连在一起。
试想很多突触连接很多神经元,不就形成了一个神经网络了吗?没错,类比到人工神经网络 (artificial neural network, ANN),也是由无数的人工神经元组成一起的,比如下左图的浅度神经网络 (shadow neural network) 和下右图的深度神经网络 (deep neural network)。

浅度神经网络适用于结构化数据 (structured data),比如像下图中 excel 里存储的二维数据。
 深度神经网络适用于等非结构化数据 (unstructured data),如下图所示的图像、文本、语音类数据。
深度神经网络适用于等非结构化数据 (unstructured data),如下图所示的图像、文本、语音类数据。

生成式 AI 模型主要是生成非结构化数据,因此了解深度神经网络是必要的。从本篇开始,我们会模型与代码齐飞,因为
Talk is cheap. Show me the code.
-- Linus Torvalds
代码都用 TensorFlow 和 Keras 来实现。

单元 A 接收图像里的像素信息。
单元 B 结合了输入像素,当原始图像中有低级特征 (low-level feature) 比如边缘 (edge) 时,发出最强信号。
单元 C 结合了低级特征,当原始图像中有高级特征 (high-level feature) 比如牙齿 (teech) 时,发出最强信号。
单元 D 结合了高级特征,当原始图像中的人微笑时,发出最强信号。
当给这个神经网络“投喂”足够多的数据,即图像,它会“找到”一组权重 (weights) 使得最终预测结果尽可能准确。找权重这个过程其实就是训练神经网络。
对神经网络有个初步认识之后,接下来的任务就是用 Keras 来实现它。
模型 (models)
层 (layers),输入 (input) 和输出 (output)
优化器 (optimizer) 和损失函数 (loss)
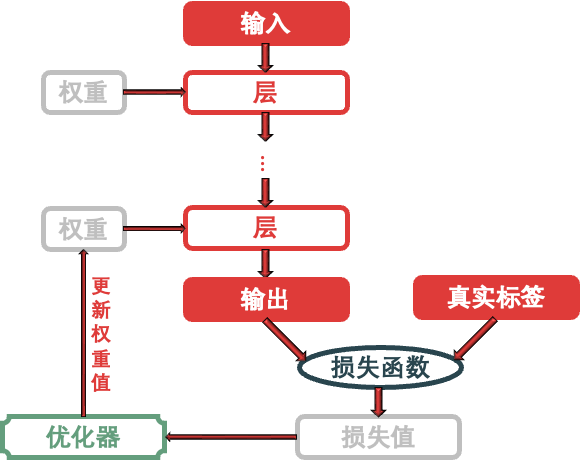
用上面的关键词来总结 Keras 训练神经网络的流程:将多个层链接在一起组成模型,将输入数据映射为预测值。然后损失函数将这些预测值输出,并与目标进行比较,得到损失值 (用于衡量网络预测值与预期结果的匹配程度),优化器利用这个损失值来更新网络的权重。
到此终于可以展示点代码了,即便是引入工具库。首先从 tensorflow.keras 库中用于搭建神经网络的模块。

整个神经网络就是一个模型,大框架的代码都来自 models 模块;模型是由多个层组成,而不同的层的代码都来自 layers 模块;模型的第一层是输入层,负责接入输入,模型的最后一层是输出层,负责提供输出,一头一尾都在 models 模块;模型骨架好了,要使它中看又中用就需要 optimizers 模块来训练它了。
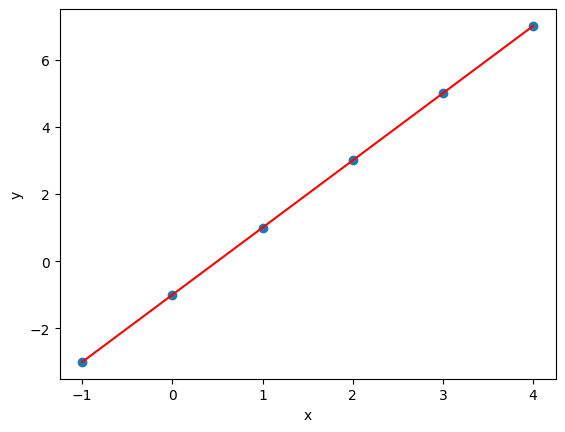
学过机器学习的同学遇到的第一个模型一定是线性回归,还是单变量的线性回归。给定一组 x 和 y 的数据:
x = [-1, 0, 1, 2, 3, 4 ]
y = [-3, -1, 1, 3, 5, 7 ]
找出 x 和 y 之间的关系,当 xnew = 10 时,问 ynew 是多少?
如下图所示,将 x 和 y 以散点的形式画出来,不难发现下图的红线就是 x 和 y 之间的关系。现在想用 Keras 杀鸡用牛刀的构建一个神经网络来求出这条红线。
用一层含一个神经元的神经网络即可,代码如下:

首先用 models.Sequential() 创建一个空神经网络,然后不断添加层,这里我们添加了 layers.Dense(),叫做稠密层。函数里面的参数 input_shape=[ 1 ] 表示输入数据的维度为 1 ,units= 1 表示输出只有 1 个神经元。可视化如下:

检查一下模型信息,奇怪的是参数个数 (下图 Param #) 居然是 2 个而不是 1 个。因为从上图来看 y = wx,只应该有 w 一个参数啊。


原因是在计算每层参数个数时,每个神经元默认会连接到一个值为 1 的偏置单元 (bias unit),因此其实上图更准确的样子如下:
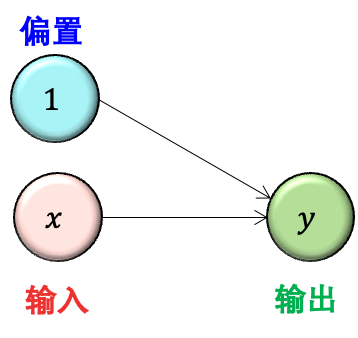
这样就对了,此时 y = wx b,有 w 和 b 两个参数了。
严格来说,其实 Dense() 函数里还是一个参数叫 activation,它字面意思是激活函数,本质上做的事情是将 wx b 以非线性的模式转换再赋予给 y。如果定义激活函数为 g,那么 y = g(wx b)。在 Keras 如果不给 activation 指定值,那么就不需要做任何非线性转换。加上激活函数这个概念,我们给出一个完整的图:
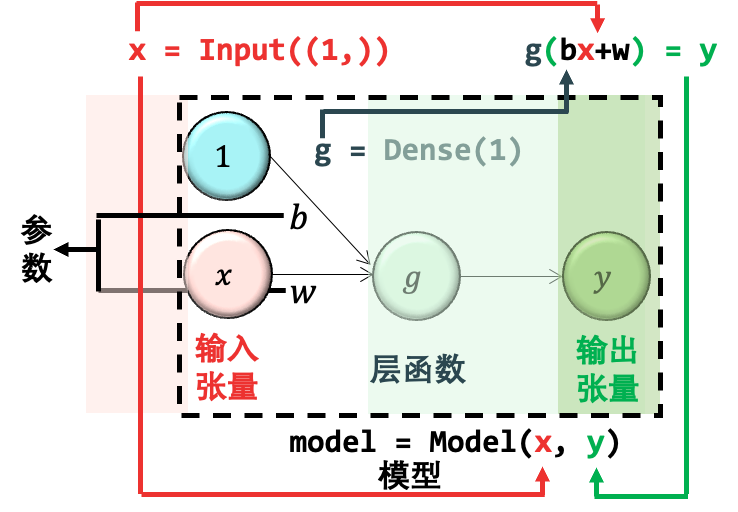
我们的目标就是求出上图中的参数,权重 w 和偏置 b。
训练模型用 fit() 函数,把数据 x 和 y 传进去。值得注意的是参数 epochs= 500 ,epoch 中文是期,即整个训练集被算法遍历的次数,这里就是遍历 500 次模型训练结束。



打印出首尾 5 期的信息,不难发现一开始 loss 很大 13.4237 ,到最后 loss 非常小只有 3.8166 e-05 ,说明在训练集里的预测值和真实值几乎一致。
模型训练之后可以用 get_weights() 函数来检查参数。
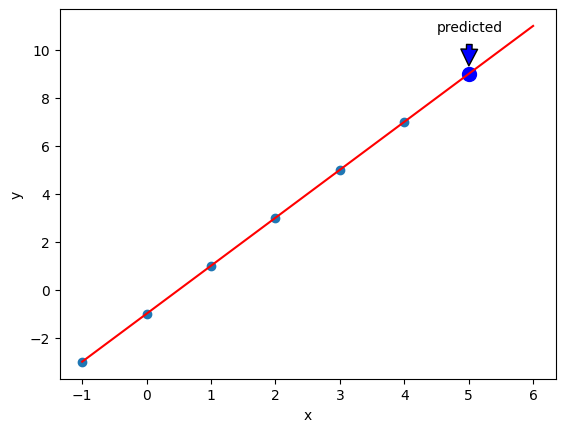
 返回结果第一个是权重 w,第二个偏置 b,因此该神经网络模型就是 y = 1.9973876 x - 0.99190086 ≈ 2 x - 1 。
返回结果第一个是权重 w,第二个偏置 b,因此该神经网络模型就是 y = 1.9973876 x - 0.99190086 ≈ 2 x - 1 。
从下图可看出,神经网络从 6 个数据 (深青点) 中“学到”了模型 (红线),而该模型可用在新数据 (蓝点) 上。
总结一下神经网络全流程:
创建模型:用 Sequential(),当然还有其他更好的方法,下节讲。
检查模型:用 summary()
编译模型:用 compile()
训练模型:用 fit()
评估模型:用 predict()
虽然本例构建了一个极简神经网络,但是五大步骤一个不少,构建复杂的神经网络也需要这五步,区别在于第 1 步创建模型时要拼接很多层,第 5 步要选择更先进的优化器,但万变不离其宗。下两节就来看看两个稍微复杂的神经网络,分别是前反馈神经网络 (feedforward neural network, FNN) 和卷积神经网络 (convoluational neural network, CNN)。
用模块 datasets 里的 load_data() 函数来下载数据并对图像的像素做归一化,原来像素在 0 到 255 之间,现在归一到 0 到 1 之间。

对于类别,用模块 utils 里的函数 to_categorical() 函数对类别进行独热编码 (one-hot encoding)。思路就是把整数用只含一个 1 的向量表示,比如类别 5 经过独热编码后变成 [ 0, 0, 0, 0, 1, 0, 0, 0, 0, 0 ],该向量有 10 个元素,和类别个数一致,向量只有第 5 个元素是 1 (独热),其他都是 0 (好冷)。

训练集的前十张图片展示如下:

上面代码给出下图所示的模型:

有了感官认识,再来研究代码。为什么需要打平层?因为图像有宽,高,色道三个维度,而打平到一维的过程如下图所示。

原始图像 ( 32, 32, 3) 输入打平层 (在参数 input_shape 指定图像维度大小),打平之后变成了一个 32* 32* 3 = 3072 的向量,可以想成现在输入有 3072 个神经元。之后三个稠密层的
神经元个数 (参数 units) 分别为 200, 150 和 10 ,前两个 200 和 150 是随便给的或者当成超参数调试出来,但最后一个 10 是和类别的个数一致。
用到的激活函数 (参数 activation) 分别是 relu, relu 和 softmax,前两个 relu 几乎是标配,但最后一个 softmax 和任务相关,如果是多分类问题就用 softmax。
常用的激活函数 (activation function) 如下图所示:

ReLU 将负输入 (x < 0) 转换成 0 , 正输入 (x > 0) 保持不变。LeakyReLU 和 ReLU 非常相似,唯一区别就是对于负输入 (x < 0),转换的结果也是一个和输入相关的负数 (ax)。
Sigmoid 将实数转换成 0-1 之间的数,而这个数可当成概率,因此 Sigmoid 函数用于二分类问题,它的延伸版 Softmax 函数用于多分类问题。
函数式建模只用记住一句话:把层当做函数用。有了这句在心,代码秒看懂。
第 1 行,用 Input() 接收图像数据。
第 2 行,把 Flatten() 当成函数 f,化简不就是 x = f(input)
第 3 行,把 Dense(units= 200, activation='relu') 当成函数 g,化简不就是 x = g(x)
第 4 行,把 Dense(units= 150, activation='relu') 当成函数 h,化简不就是 x = h(x)
第 5 行,把 Dense(units= 10, activation='softmax') 当成函数 q,化简不就是 output = q(x)
这样一层层函数接着函数把 input 传递到 output,output = q(h(g(f(input)))),最后再用 models.Model 将它俩建立关系。

该模型自动被命名 “model”,接着一张表分别描述每层的名称类型 (layer (type))、输出形状 (Output Shape) 和参数个数 (Param #)。我们一层层来看
InputLayer 层被命名成 input_ 1 ,输出形状为 [None, 32, 32, 3 ],后面三个元素对应着图像宽、高和色道,第一个 None 其实代表的样本数,更严谨的讲是一批 (batch) 里面的样本数。为了代码简洁,这个样本数在建模时通常不需要显性写出来。
Flatten 层被命名成 flatten, 3072 就是 32* 32* 3 打平之后的个数,参数个数为 0 ,因为打平只是重塑数组,不需要任何参数来完成重塑动作。
第一个 Dense 层被命名为 dense,输出形状是 200 ,参数 614, 600 = ( 3072 1) * 200 ,不要忘了有偏置单元。
第二个 Dense 层被命名为 dense_ 1 ,输出形状是 150 ,参数 30, 150 = ( 200 1) * 150 ,同样考虑偏置单元。
第三个 Dense 层被命名为 dense_ 2 ,输出形状是 10 ,参数 1, 510 = ( 150 1) * 10 ,同样考虑偏置单元。
最下面还列出总参数量 (Total params) 646, 260 ,可训练参数量 (Trainable params) 646, 260 ,不可训练参数量 (Non-trainable params) 0 。为什么还有参数不需要训练呢?你想想迁移学习,把借过来的网络锁住开始的 n 层,只训练最后 1- 2 层,那前面 n 层的参数可不就不参与训练吗?
根据要解决的任务来选择损失函数
选取理想的优化器
选取想监控的指标
编译模型用 complie() 函数,代码如下:

在 complie() 函数中:
对于参数 loss,本例是十分类问题,因此用的损失函数是 categorical_crossentropy,此外:
二分类问题:损失函数是 binary_crossentropy
回归问题:损失函数是 mean_squared_error
对于参数 optimizer,大多数情况下,使用 adam 和 rmsprop 优化器及其默认的学习率是稳妥的。在设定该参数时,也可以通过用名称和实例化对象来调用。
名称:'sgd'
对象:optimizers.Adam(learning_rate= 0.0005)
对于参数 metrics,也可以通过用名称和实例化对象来调用,在本例中的指标是精度,那么可写成
名称:['accuracy']
对象:[metrics.categorical_accuracy]
注意,指标不会影响模型的训练过程,只是让我们监控模型训练时的表现,损失函数才会影响模型的训练过程。
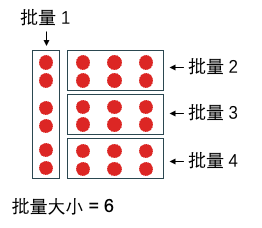
批量大小 (batch size) 指一个批量里的样本个数。下例中总共有 24 个数据,如果每个批里有 6 个数据,那么总局可分成 4 批。
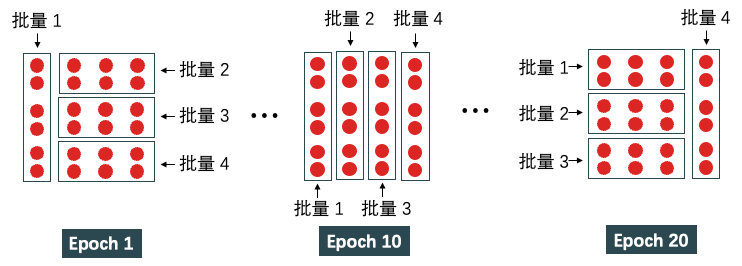
期(epoch)指整个训练集被算法遍历一次。当设 epoch 为 20 时,那么要以不同的方式遍历整个训练集 20 次。一次 epoch 要经历 4 次迭代才能遍历整个数据集,即样本总数 / 批量大小 = 24 / 6 次迭代。20 次 epoch 运行过程如下图所示。
训练模型用 fit() 函数,代码如下:


上图给出训练步骤,不难看出训练集被分成 1563 个堆,每堆含 32 张图 (batch size)。10 个 epoch 之后,损失函数 (categorical cross-entropy) 从 1.8472 降到 1.3696 ,同时准确率 (accuracy) 从 33.41% 提升到 51.39% 。模型在训练集上可以到达 51.39% 的准确率,那么它在没见过的数据集上的表现会如何呢?

模型在测试集上的准确率为 49.52% ,比随机预测一个类别的准确率 10% 高多了 (因为有十类)。由于我们用这样一个非常简单的前馈神经网络来预测图片类别,49.52% 的准确率已经算是不错的结果了。
用 predict() 函数比对预测和真实类别。

测试集里用 10, 000 张图,类别是 10 个,因此 preds 是一个 [ 10000, 10 ] 的数组,每一行都是模型对相应图片预测的 10 个类别的概率,当然所有概率加起来等于 1 。看看测试集里第一张图片的预测结果:


y_test 也是一个 [ 10000, 10 ] 的数组,每一行都是相应图片真实的类别,因此 10 个元素有 9 个零和 1 个一。看看测试集里第一张图片的真实类别:


不难看出,预测结果 preds[ 0,:] 中类别四的概率最高 0.38579068 ,而真实类别 test[ 0.:] 就是类别四 (第 4 个元素是一)。用 np.argmax 分别从预测结果 preds[ 0,:] 和真实类别 test[ 0.:] 中找到最大值对应的索引,并从 CLASSES 中映射出类别描述。

测试集第一张是猫,而模型预测的也是猫,做对了!
再试试第四张。

测试集第四张是船,但模型预测的是飞机,做错了!
可视化:上面的对比方法太麻烦,我们可以随机抽取测试集里的 10 张,打印出每张图片,在图片下还贴上模型预测类别和其真实类别。


从上面 10

















